The core task of many, many games is to move forward through a hazard-filled “tunnel”. (Examples: Half-Life, Sly Cooper 1.) This is economical from a storytelling perspective: you know fairly accurately what players will have seen at any given point, and you can closely control how they encounter each situation.
From a content-production standpoint, though, the tunnel design is fairly wasteful. The reward for making progress is to see what comes next, so you can't afford to have the environment look too repetitive. In addition, players move through each part of the world once and then go on, never to return. If you've played the vehicle levels in Half-Life 2, or the rail-grind sequences in the original Ratchet and Clank, you know that in addition to seeing each part of the level once, players tend to see it only briefly. This is expensive.
As computers get more powerful they are capable of displaying higher-resolution textures, higher-detail models, and so forth. Environments take increasingly more time and money to construct. As a result, game designers are trying to induce the player to spend more time in the same place. I think of this as “arena” game design.
Later Ratchet and Clank games dropped the rail-grind sequences because they weren't cost-effective. (Rail-grind sequences are back in the latest installment. Insomniac must have found ways to bring their costs in line with the rest of the game. You can probably guess some ways from looking at it.) Later Sly Cooper games adopted a hub model, with a large central world that had lots of missions set in the same environment. Games like Grand Theft Auto take this to its logical conclusion. There are no distinct levels, just a single, large world.
Designers also use collectibles to encourage players to spend time looking at all the expensive scenery. Urban Chaos, a game by defunct developer Muckyfoot that came out the year before Grand Theft Auto 3 had similar gameplay to the GTA series. It had powerups tucked away in corners of the worlds which would give your character permanent boosts in speed, strength, and so forth. Not unlike Crackdown, really, to name a more recent example. It would be amusing to make a collectible out of the world's triangles themselves.
Monday, December 31, 2007
Monday, December 24, 2007
Scripting languages
I've been busy this week with the new baby so I haven't done more than a few minutes of programming.
Issue Trackers
I did look at wikipedia's big list of issue trackers again to see if something wonderful has appeared. Sadly, no. I used FogBugz here at home until my server crashed. It turns out the version I've got doesn't work well with Vista, so I haven't gotten it going again. I've used (not administered) various other web-based bug trackers at my various jobs. Web-based is inherently sluggish and icky-interfaced and usually requires a Linux server and/or facility with setting up an ecosystem of database, scripting language, and web server that I don't possess. I keep hoping there will be some open-source tracker that just installs and works and doesn't require a bunch of steps. FogBugz came pretty close, although I think I still had to mess around with my IIS settings. And it is web-based. Sigh.
My life in scripting languages
Over the years I've worked on a variety of games, some of which shipped. Nearly all of them used at least two programming languages.
The first game I worked on was Blade Runner, a modestly successful point-and-click adventure game. The game was coded entirely in C/C++ except for a small amount of assembly language in the renderer. There were three engine programmers and five scripting programmers. The scripting language was C. We used Windows' DLL interface to dynamically load the code for each location in the game. The script DLL's interface to the game was well-defined, consisting of a header file full of functions to do things like play lines of dialog, play animations, and check or set game state flags.
Later, I worked on Loose Cannon, an ill-fated project that was begun by Digital Anvil for Microsoft, sold to Ubisoft and given to Sinister Games (where I was) to finish. After two or three years there it was canceled. I learned a lot from that project, and perhaps the most important lesson was:
The code may leak memory like a sieve (Loose Cannon), contain its own hacky implementation of vtables, or use Hungarian notation that drains a little bit of your soul every day you have to look at it. You may be filled with loathing for the code; it doesn't matter. All code is loathsome, in its own way. Learn to do mechanical modification of code; you'd be surprised what you can do step by step while preserving a working game.
But I digress. One of the restarts involved trying to write the game in Python, with the idea that we would reimplement functionality in optimized C++ as necessary. That effort didn't get terribly far beyond the point of driving a car over the landscape at two frames a second. I have heard tell of shipped games (the Pirates! remake, for one) that use Python as the top-level language, though, so it's not impossible.
After that I helped finish Psi-Ops, a sleeper hit third-person action game featuring your typical brawny, buzz-cut Caucasian super-soldier, albeit augmented in this case with psychic superpowers. (The big debate was whether to name him Jack or Nick.)
Psi-Ops used C/C++ as its primary language, as does practically every game, with Python for scripting. The C++/Python interface was modeled on Boost.Python. We could do gnarly things like deriving a Python class from a C++ class, then deriving a C++ class from the Python class. There were about a dozen programmers, and I think they were all bilingual with regards to the programming. There were a half dozen designers, but if my memory serves, they did not do much (if any) Python scripting.
Finally, I worked on Sly 3, which used (a variant of) Scheme as its scripting language. The use of Scheme dates back to Sly 1 or 2 so I can't say for certain why it was chosen, but my hunch is that it was a combination of:
Why Have a Scripting Language?
Why would you use more than one language to write a game?
There are certainly some big negatives to overcome for it to be a net gain. You wind up writing and maintaining an interface layer between the two languages. The two languages will compete for control of memory and you will have to work out how they should share it. You also have to decide what each language is for: how to decide which language to use to implement any given piece of functionality. You have to train programmers in both languages and in the ways the game's concepts are represented in each. If one of the languages is home-grown, it probably has terrible or nonexistent editing, compiling, and debugging tools.
Despite all this, game programmers keep including scripting languages in their projects. Here are the reasons I can think of:
To a large degree, the productivity of your day can be measured by the number of edit/build/load/test cycles you are able to perform. If the build/load phase takes five minutes, say, then you've got a maximum of 96 cycles in an eight-hour workday. The link phase, in particular, can get rather long (i.e. minutes) for some of the C++ compilers that game developers have to work with. Programmers look for ways to bypass as much of the link and load phases as possible, and scripting languages are seen as a way to do this.
Another reason often cited is to devolve some of the programming duties onto less-expensive programmers (a.k.a. designers). Scripting languages are expected to be simpler to use (by having no pointers, say, or no explicit type annotation), and thus more suitable for use by inexperienced programmers.
Bolting on a scripting language may be a way to use a more productive programming language for the parts of the game where performance is less critical. Languages that support higher levels of abstraction allow you to do more with less typing. Languages with more advanced type systems can verify more properties of your program before it is run, reducing the number of edit/test cycles needed.
Finally, we can't discount that programmers love to complicate things. If we don't have enough problems to solve we will create them! Let's face it: C++ is not a sexy language. It just happens to be the current language of choice for console development. There are lots of other languages that are more popular or exciting and it's fun to use them.
It is very important when you are responsible for a scripting language in a game not to lose sight of the goals. For instance, a scripting language may reduce the build time, but in my experience we've ended up gaining back a lot of the build time as we strive to make the game more efficient. (There's a conflict between malleability and efficiency.) Scripting languages may be simpler; but if they lack good abstraction capabilities (and people who know how to use them) you can end up with copy/paste code monstrosities. In addition, the use of dynamic languages defers detection of the most common types of errors (typos and signature mismatches) to runtime, which means more edit/test cycles.
Over the years I haven't been able to help thinking that the approach we used on Blade Runner was perhaps one of the best. By using a mainstream language, we ensured that our scripters had an integrated development environment. The compiler gave good error messages, and if they had a problem we could easily debug it. By having a clear, simple interface to the game we ensured that compile times were fast. The DLL mechanism ensured that link times were fast, too. Having a single language meant that there weren't any interface issues regarding memory usage, or object representation, to worry about.
If you do end up using a scripting language, please don't roll your own! It may sound like fun, but you have only to look at Maya's Mel language to see the horrors this can inflict on people. Autodesk (the current owners of Maya) have grafted Python onto Maya so that people won't have to deal with their misbegotten scripting language any more than necessary.
Issue Trackers
I did look at wikipedia's big list of issue trackers again to see if something wonderful has appeared. Sadly, no. I used FogBugz here at home until my server crashed. It turns out the version I've got doesn't work well with Vista, so I haven't gotten it going again. I've used (not administered) various other web-based bug trackers at my various jobs. Web-based is inherently sluggish and icky-interfaced and usually requires a Linux server and/or facility with setting up an ecosystem of database, scripting language, and web server that I don't possess. I keep hoping there will be some open-source tracker that just installs and works and doesn't require a bunch of steps. FogBugz came pretty close, although I think I still had to mess around with my IIS settings. And it is web-based. Sigh.
My life in scripting languages
Over the years I've worked on a variety of games, some of which shipped. Nearly all of them used at least two programming languages.
The first game I worked on was Blade Runner, a modestly successful point-and-click adventure game. The game was coded entirely in C/C++ except for a small amount of assembly language in the renderer. There were three engine programmers and five scripting programmers. The scripting language was C. We used Windows' DLL interface to dynamically load the code for each location in the game. The script DLL's interface to the game was well-defined, consisting of a header file full of functions to do things like play lines of dialog, play animations, and check or set game state flags.
Later, I worked on Loose Cannon, an ill-fated project that was begun by Digital Anvil for Microsoft, sold to Ubisoft and given to Sinister Games (where I was) to finish. After two or three years there it was canceled. I learned a lot from that project, and perhaps the most important lesson was:
Starting over from scratch is the wrong thing to do.
The code may leak memory like a sieve (Loose Cannon), contain its own hacky implementation of vtables, or use Hungarian notation that drains a little bit of your soul every day you have to look at it. You may be filled with loathing for the code; it doesn't matter. All code is loathsome, in its own way. Learn to do mechanical modification of code; you'd be surprised what you can do step by step while preserving a working game.
But I digress. One of the restarts involved trying to write the game in Python, with the idea that we would reimplement functionality in optimized C++ as necessary. That effort didn't get terribly far beyond the point of driving a car over the landscape at two frames a second. I have heard tell of shipped games (the Pirates! remake, for one) that use Python as the top-level language, though, so it's not impossible.
After that I helped finish Psi-Ops, a sleeper hit third-person action game featuring your typical brawny, buzz-cut Caucasian super-soldier, albeit augmented in this case with psychic superpowers. (The big debate was whether to name him Jack or Nick.)
Psi-Ops used C/C++ as its primary language, as does practically every game, with Python for scripting. The C++/Python interface was modeled on Boost.Python. We could do gnarly things like deriving a Python class from a C++ class, then deriving a C++ class from the Python class. There were about a dozen programmers, and I think they were all bilingual with regards to the programming. There were a half dozen designers, but if my memory serves, they did not do much (if any) Python scripting.
Finally, I worked on Sly 3, which used (a variant of) Scheme as its scripting language. The use of Scheme dates back to Sly 1 or 2 so I can't say for certain why it was chosen, but my hunch is that it was a combination of:
- a programmer with an MIT degree and
- very little time
Why Have a Scripting Language?
Why would you use more than one language to write a game?
There are certainly some big negatives to overcome for it to be a net gain. You wind up writing and maintaining an interface layer between the two languages. The two languages will compete for control of memory and you will have to work out how they should share it. You also have to decide what each language is for: how to decide which language to use to implement any given piece of functionality. You have to train programmers in both languages and in the ways the game's concepts are represented in each. If one of the languages is home-grown, it probably has terrible or nonexistent editing, compiling, and debugging tools.
Despite all this, game programmers keep including scripting languages in their projects. Here are the reasons I can think of:
To a large degree, the productivity of your day can be measured by the number of edit/build/load/test cycles you are able to perform. If the build/load phase takes five minutes, say, then you've got a maximum of 96 cycles in an eight-hour workday. The link phase, in particular, can get rather long (i.e. minutes) for some of the C++ compilers that game developers have to work with. Programmers look for ways to bypass as much of the link and load phases as possible, and scripting languages are seen as a way to do this.
Another reason often cited is to devolve some of the programming duties onto less-expensive programmers (a.k.a. designers). Scripting languages are expected to be simpler to use (by having no pointers, say, or no explicit type annotation), and thus more suitable for use by inexperienced programmers.
Bolting on a scripting language may be a way to use a more productive programming language for the parts of the game where performance is less critical. Languages that support higher levels of abstraction allow you to do more with less typing. Languages with more advanced type systems can verify more properties of your program before it is run, reducing the number of edit/test cycles needed.
Finally, we can't discount that programmers love to complicate things. If we don't have enough problems to solve we will create them! Let's face it: C++ is not a sexy language. It just happens to be the current language of choice for console development. There are lots of other languages that are more popular or exciting and it's fun to use them.
It is very important when you are responsible for a scripting language in a game not to lose sight of the goals. For instance, a scripting language may reduce the build time, but in my experience we've ended up gaining back a lot of the build time as we strive to make the game more efficient. (There's a conflict between malleability and efficiency.) Scripting languages may be simpler; but if they lack good abstraction capabilities (and people who know how to use them) you can end up with copy/paste code monstrosities. In addition, the use of dynamic languages defers detection of the most common types of errors (typos and signature mismatches) to runtime, which means more edit/test cycles.
Over the years I haven't been able to help thinking that the approach we used on Blade Runner was perhaps one of the best. By using a mainstream language, we ensured that our scripters had an integrated development environment. The compiler gave good error messages, and if they had a problem we could easily debug it. By having a clear, simple interface to the game we ensured that compile times were fast. The DLL mechanism ensured that link times were fast, too. Having a single language meant that there weren't any interface issues regarding memory usage, or object representation, to worry about.
If you do end up using a scripting language, please don't roll your own! It may sound like fun, but you have only to look at Maya's Mel language to see the horrors this can inflict on people. Autodesk (the current owners of Maya) have grafted Python onto Maya so that people won't have to deal with their misbegotten scripting language any more than necessary.
Monday, December 17, 2007
Failed word graph gameplay
I've been thinking about ways to make a game based on the graph of words that differ by one letter. There's the puzzle type that originally got me thinking about this, with two words separated by blanks to fill in. That's not much of a game, though; more of a puzzle.
I had the idea of moving around through the graph, discovering words along the way. My first idea was of a 4X space exploration type of game, where each word would represent a star system, and the adjacencies would represent wormholes (wordholes?) between them.
There are a lot of unknowns about this idea. The main unknown for me is how the graph feels. How do you map it to a plane? Is the connectivity tractable for human brains? There are 2415 connected four-letter words. This seems like rather a lot of stars for a typical space game, and there's not necessarily an easy way to restrict the player to a subset of words, since they've already got all the words in their head.
My second idea was to score the player on the longest chain of adjacent words they can string together without revisiting a word they've already used. This puts an element of Hamiltonian pathfinding into the mix.
To test this gameplay I took my DOS 80x25 text console simulator and threw together a prototype of moving through the graph. Each word you type goes in the center of the screen, and the adjacent words are placed around it. I put question marks for words you haven't typed yet.

“Ware” has the most neighbors (25) so I used it when deciding how to lay out the neighbors.
Words form into groups based on which letter is varying. Four-letter words belong to up to four groups. Since I was dealing with a text grid, I tried splitting the words into the four groups and putting them in clusters next to the current word.
It ought to be possible to represent further graph connections to some extent. I've thought of listing words that are two steps away horizontally, extending out from each of the cyan one-step words in the picture above. I don't think there's space in my 80x25 layout to list all words in every case, though. There is also the issue that two one-step words may both have links to the same two-step word. In this case, would you list the word in both places? In a graphical graph representation you could try to put the words next to each other so they could both point to a single node for the two-step word.
Grouping words like I've done in the picture may give away too much of the graph structure. In particular, listing the words alphabetically as I've done gives away too much. It's not that hard to come up with the missing words.
More problematic, though, is the longest-path gameplay. It turns out to be pretty easy to keep going, and going, and going, so you're likely to succumb to boredom before you complete a scoring run. Also, with me showing only one step ahead in the graph, you don't really see dead-ends coming so there isn't much chance for strategy as you choose words.
Any ideas for gameplay involving the word adjacency graph?
I had the idea of moving around through the graph, discovering words along the way. My first idea was of a 4X space exploration type of game, where each word would represent a star system, and the adjacencies would represent wormholes (wordholes?) between them.
There are a lot of unknowns about this idea. The main unknown for me is how the graph feels. How do you map it to a plane? Is the connectivity tractable for human brains? There are 2415 connected four-letter words. This seems like rather a lot of stars for a typical space game, and there's not necessarily an easy way to restrict the player to a subset of words, since they've already got all the words in their head.
My second idea was to score the player on the longest chain of adjacent words they can string together without revisiting a word they've already used. This puts an element of Hamiltonian pathfinding into the mix.
To test this gameplay I took my DOS 80x25 text console simulator and threw together a prototype of moving through the graph. Each word you type goes in the center of the screen, and the adjacent words are placed around it. I put question marks for words you haven't typed yet.

“Ware” has the most neighbors (25) so I used it when deciding how to lay out the neighbors.
Words form into groups based on which letter is varying. Four-letter words belong to up to four groups. Since I was dealing with a text grid, I tried splitting the words into the four groups and putting them in clusters next to the current word.
It ought to be possible to represent further graph connections to some extent. I've thought of listing words that are two steps away horizontally, extending out from each of the cyan one-step words in the picture above. I don't think there's space in my 80x25 layout to list all words in every case, though. There is also the issue that two one-step words may both have links to the same two-step word. In this case, would you list the word in both places? In a graphical graph representation you could try to put the words next to each other so they could both point to a single node for the two-step word.
Grouping words like I've done in the picture may give away too much of the graph structure. In particular, listing the words alphabetically as I've done gives away too much. It's not that hard to come up with the missing words.
More problematic, though, is the longest-path gameplay. It turns out to be pretty easy to keep going, and going, and going, so you're likely to succumb to boredom before you complete a scoring run. Also, with me showing only one step ahead in the graph, you don't really see dead-ends coming so there isn't much chance for strategy as you choose words.
Any ideas for gameplay involving the word adjacency graph?
Shipped!
Yesterday we finally delivered a product that's been in the works for nine months. I did conceptual work and production assistance; my wife did the rest. We named her Esther.
Monday, December 10, 2007
Boobs, Booty, and Booze: Adventures In Edit Distance
This week I got to thinking about word puzzles like this:
Fill in the four intermediate words. Each word is four letters long and differs by exactly one letter from the word above it and the word below it.
This is an example of a type of minimum edit distance. “Spry” is five steps away from “moat” when each step consists of changing a single letter.
How can puzzles like this be created? How can a puzzle's difficulty be evaluated? What does the space of possible puzzles look like?
To answer these questions, I went to wordlist.sourceforge.net and picked up the 12dicts package. This is a collection of word lists which have been compiled from twelve dictionaries. I chose the 2of12inf list, which contains any word listed in at least two of the twelve dictionaries, plus all of that word's inflections.
After filtering the list to words of a specific length the next step is to build an adjacency graph. I tried brute force first: a doubly-nested loop over all the words, testing each pair to see if they were adjacent. This takes a very long time. As an example, with the 2,546 four-letter words there are 3,242,331 pairs of words to consider.
Because the graph is pretty sparse there are much faster ways to build it. One way is to consider each letter position in turn, sorting the words into groups in which all the other letters are the same. All the words in a given group are neighbors of each other. Here's an implementation in Python:
Once we have the graph structure in hand we can begin analyzing it in various ways. The simplest is to identify words that have no adjacencies. For instance, “sexy” and “odor” stand alone. These words can't be used in puzzles.
These “loner” words are a special case of identifying the connected components of the graph. These are the groups of words that are interconnected. A puzzle needs to have both of its endpoints in the same connected component or it won't be solvable. The basic algorithm for identifying connected components is to flood-fill from every word that hasn't already been visited, keeping track of all the words collected on each fill.
It turns out that, for lengths of three to six letters, most words belong to a single large connected component. As words get longer, they become less and less interconnected and the number of components increases rapidly.
In the table above, Adjacencies are the number of edges in the graph. Loners counts connected components with only a single word. Groups counts components with two or more words. Biggest is the size of the largest group.
The final column, Bridges, counts edges which, if removed, break a component into two separate pieces. These represent the word transformations which you might expect to use frequently, since they are the only way to get from words on one side to words on the other side.
As it happens, though, words tend to be very well connected, and so there are never more than 20 or so words on one side of a bridge. Most of the time there is only one word on the other side of the bridge, i.e. the word is a dead-end with only one neighbor. An example of a dead-end is the word SPRY in the puzzle above. There is only one possible word to go above it in the puzzle (at least in my dictionary).
The diagram below shows several bridges in the five-letter word graph.

The edge between boozy and booze represents the most common sort of bridge, dividing one word from the rest. In comparison, cutting the edge between booby and bobby isolates nine words. Other bridges are the edge from hobby to hubby, and from tubby to tabby.
The algorithm for finding bridges took a while for me to understand. It's hinted at in the exercises of Introduction to Algorithms (Corman, Leiserson, Rivest) and is built on a depth-first traversal of the graph. I found pseudocode for it but it happens to be incorrect.
The gist of it is that, if you do a depth-first traversal, any edges you find that point at already-visited nodes are back edges: they close a loop, meaning that none of the edges on that loop can be bridges. Related to this, all bridge edges must be edges of the tree produced by the depth-first traversal. During the recursive descent of the depth-first traversal you can compute the highest (closest to root) position that each subtree points to. If a subtree does not point to a node outside of itself, then the edge to that subtree is a bridge.
Another metric for good words to know is the words with the most connections. For example, here are the top few words of length four, along with how many neighboring words each has:
I'm out of time now, and haven't gotten to the questions of generating puzzles or evaluating their difficulty. Difficulty might be a function of how many choices you have at each step of the puzzle, combined with the relative frequency of each of the words in the English language (and hence, how likely you are to know them). Nevertheless, I feel I understand the word space a lot better, and have managed to generate some interesting puzzles along the way. I find that five steps is about the maximum that I can reasonably do. There are minimum paths that get up to 17 and higher steps, though.
MOAT
____
____
____
____
SPRY
Fill in the four intermediate words. Each word is four letters long and differs by exactly one letter from the word above it and the word below it.
This is an example of a type of minimum edit distance. “Spry” is five steps away from “moat” when each step consists of changing a single letter.
How can puzzles like this be created? How can a puzzle's difficulty be evaluated? What does the space of possible puzzles look like?
To answer these questions, I went to wordlist.sourceforge.net and picked up the 12dicts package. This is a collection of word lists which have been compiled from twelve dictionaries. I chose the 2of12inf list, which contains any word listed in at least two of the twelve dictionaries, plus all of that word's inflections.
After filtering the list to words of a specific length the next step is to build an adjacency graph. I tried brute force first: a doubly-nested loop over all the words, testing each pair to see if they were adjacent. This takes a very long time. As an example, with the 2,546 four-letter words there are 3,242,331 pairs of words to consider.
Because the graph is pretty sparse there are much faster ways to build it. One way is to consider each letter position in turn, sorting the words into groups in which all the other letters are the same. All the words in a given group are neighbors of each other. Here's an implementation in Python:
adjacent_words = {}
for i in range(word_len):
grouped_words = {}
for word in words:
group = word[:i] + word[i+1:]
grouped_words.setdefault(group, []).append(word)
for group_words in grouped_words.itervalues():
for word1 in group_words:
for word2 in group_words:
if word1 != word2:
adjacent_words.setdefault(word1, set()).add(word2)
Once we have the graph structure in hand we can begin analyzing it in various ways. The simplest is to identify words that have no adjacencies. For instance, “sexy” and “odor” stand alone. These words can't be used in puzzles.
These “loner” words are a special case of identifying the connected components of the graph. These are the groups of words that are interconnected. A puzzle needs to have both of its endpoints in the same connected component or it won't be solvable. The basic algorithm for identifying connected components is to flood-fill from every word that hasn't already been visited, keeping track of all the words collected on each fill.
It turns out that, for lengths of three to six letters, most words belong to a single large connected component. As words get longer, they become less and less interconnected and the number of components increases rapidly.
| Length | Words | Adjacencies | Loners | Groups | Biggest | Bridges |
|---|---|---|---|---|---|---|
| 3 | 642 | 3840 | 11 | 1 | 631 | 9 |
| 4 | 2546 | 11476 | 79 | 19 | 2415 | 125 |
| 5 | 5122 | 12435 | 613 | 179 | 3935 | 547 |
| 6 | 8303 | 11218 | 2239 | 670 | 3943 | 752 |
| 7 | 11571 | 10039 | 4689 | 1173 | 2235 | 9 |
| 8 | 12687 | 5012 | 7052 | 1695 | 433 | 0 |
| 9 | 11768 | 2426 | 8135 | 1467 | 37 | 3 |
| 10 | 9896 | 1525 | 7388 | 1103 | 21 | 2 |
| 11 | 7362 | 905 | 5820 | 699 | 14 | 1 |
| 12 | 5067 | 500 | 4155 | 433 | 6 | 0 |
In the table above, Adjacencies are the number of edges in the graph. Loners counts connected components with only a single word. Groups counts components with two or more words. Biggest is the size of the largest group.
The final column, Bridges, counts edges which, if removed, break a component into two separate pieces. These represent the word transformations which you might expect to use frequently, since they are the only way to get from words on one side to words on the other side.
As it happens, though, words tend to be very well connected, and so there are never more than 20 or so words on one side of a bridge. Most of the time there is only one word on the other side of the bridge, i.e. the word is a dead-end with only one neighbor. An example of a dead-end is the word SPRY in the puzzle above. There is only one possible word to go above it in the puzzle (at least in my dictionary).
The diagram below shows several bridges in the five-letter word graph.

The edge between boozy and booze represents the most common sort of bridge, dividing one word from the rest. In comparison, cutting the edge between booby and bobby isolates nine words. Other bridges are the edge from hobby to hubby, and from tubby to tabby.
The algorithm for finding bridges took a while for me to understand. It's hinted at in the exercises of Introduction to Algorithms (Corman, Leiserson, Rivest) and is built on a depth-first traversal of the graph. I found pseudocode for it but it happens to be incorrect.
The gist of it is that, if you do a depth-first traversal, any edges you find that point at already-visited nodes are back edges: they close a loop, meaning that none of the edges on that loop can be bridges. Related to this, all bridge edges must be edges of the tree produced by the depth-first traversal. During the recursive descent of the depth-first traversal you can compute the highest (closest to root) position that each subtree points to. If a subtree does not point to a node outside of itself, then the edge to that subtree is a bridge.
Another metric for good words to know is the words with the most connections. For example, here are the top few words of length four, along with how many neighboring words each has:
ware: 25
pats: 24
wine: 24
bale: 23
bare: 23
care: 23
core: 23
mare: 23
mate: 23
paps: 23
tars: 23
bars: 22
caps: 22
cars: 22
done: 22
line: 22
lore: 22
male: 22
mats: 22
mine: 22
pale: 22
pare: 22
pits: 22
tons: 22
tots: 22
I'm out of time now, and haven't gotten to the questions of generating puzzles or evaluating their difficulty. Difficulty might be a function of how many choices you have at each step of the puzzle, combined with the relative frequency of each of the words in the English language (and hence, how likely you are to know them). Nevertheless, I feel I understand the word space a lot better, and have managed to generate some interesting puzzles along the way. I find that five steps is about the maximum that I can reasonably do. There are minimum paths that get up to 17 and higher steps, though.
Monday, December 3, 2007
Powered trajectory plot
Soonest-descent trajectory
I've spent a bit of time attempting to simplify the math for the soonest-descent trajectory angle. The basic equation relates the rocket angle (which is presumed to be held constant during the horizontal braking phase) to the difference between the height when horizontal braking finishes and the height at which vertical braking must start.
The equation ends up having the sine of the rocket angle in its denominators, which means it gets squirrelly near zero. However, as you can see in the last plot from two weeks ago, the curve does not look complicated at all, and it looks well-behaved at zero.
It turns out that the equation can be simplified down to this form:

If that was all we knew about the equation, we'd be stuck. However, it turns out that the constants b and c will always have opposite signs. Likewise d and e will have opposite signs. This means that their respective terms cancel each other out as the angle approaches zero. I figured this out by writing out the series expansions for the sines and cosines.
On a separate note, I put a very simple solver for the equation into my lander game and draw an arrow indicating the direction to fire the rocket for soonest descent. It turns out that, if horizontal braking finishes at the same instant that vertical braking starts (which is what the equation is aiming for), there's often quite a large instantaneous turn necessary. This is hard to fly. If I was intending to produce a flyable trajectory I'd need to add in sufficient time for the rocket to turn upright before commencing vertical braking.
Powered trajectory plot
The ballistic trajectory plot has turned out to be very useful. It shows you where the rocket will go if you don't do anything. I got to thinking that perhaps a similar plot for powered flight might be useful. The idea is to show where the rocket will go if you keep the rocket firing continuously but don't do any additional steering. (My rocket attitude is defined in screen space, which rotates to keep the rocket at the top of the screen, so technically the rocket does rotate when you don't do anything. This turned out to be the most useful frame of reference for controlling rocket direction.)
The powered trajectory plot allows you to swivel the rocket and experimentally find the horizontal braking trajectory that I was aiming for in the section above. Here's a sample:





I may cut off the trajectory plot when (local) horizontal velocity reaches zero. It would also be good to mark that point with a circle or something so it's clear. Next, I plan to compute the height at which vertical braking must start at the point where horizontal velocity reaches zero. This could be color-coded based on whether it's above or below the height where the rocket stop moving horizontally. Using this you can visually solve the equation to figure out how to fly an approach trajectory.
I've spent a bit of time attempting to simplify the math for the soonest-descent trajectory angle. The basic equation relates the rocket angle (which is presumed to be held constant during the horizontal braking phase) to the difference between the height when horizontal braking finishes and the height at which vertical braking must start.
The equation ends up having the sine of the rocket angle in its denominators, which means it gets squirrelly near zero. However, as you can see in the last plot from two weeks ago, the curve does not look complicated at all, and it looks well-behaved at zero.
It turns out that the equation can be simplified down to this form:

If that was all we knew about the equation, we'd be stuck. However, it turns out that the constants b and c will always have opposite signs. Likewise d and e will have opposite signs. This means that their respective terms cancel each other out as the angle approaches zero. I figured this out by writing out the series expansions for the sines and cosines.
On a separate note, I put a very simple solver for the equation into my lander game and draw an arrow indicating the direction to fire the rocket for soonest descent. It turns out that, if horizontal braking finishes at the same instant that vertical braking starts (which is what the equation is aiming for), there's often quite a large instantaneous turn necessary. This is hard to fly. If I was intending to produce a flyable trajectory I'd need to add in sufficient time for the rocket to turn upright before commencing vertical braking.
Powered trajectory plot
The ballistic trajectory plot has turned out to be very useful. It shows you where the rocket will go if you don't do anything. I got to thinking that perhaps a similar plot for powered flight might be useful. The idea is to show where the rocket will go if you keep the rocket firing continuously but don't do any additional steering. (My rocket attitude is defined in screen space, which rotates to keep the rocket at the top of the screen, so technically the rocket does rotate when you don't do anything. This turned out to be the most useful frame of reference for controlling rocket direction.)
The powered trajectory plot allows you to swivel the rocket and experimentally find the horizontal braking trajectory that I was aiming for in the section above. Here's a sample:


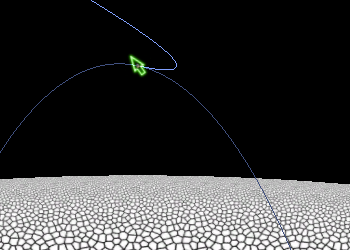

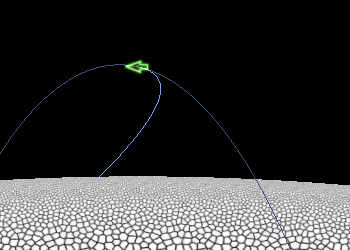
I may cut off the trajectory plot when (local) horizontal velocity reaches zero. It would also be good to mark that point with a circle or something so it's clear. Next, I plan to compute the height at which vertical braking must start at the point where horizontal velocity reaches zero. This could be color-coded based on whether it's above or below the height where the rocket stop moving horizontally. Using this you can visually solve the equation to figure out how to fly an approach trajectory.
Subscribe to:
Comments (Atom)